从实习面试到 Agent 开发:名词换得比模型还快,我为什么不焦虑
Prompt → Context → Harness → Loop,名词换得比模型还快,但底层那件事从没变:你需要的不是追上每个新词,而是一个能持续跑下去的系统。
上周在粉丝群做了场技术分享,视频已经发出来了。但总有人更习惯读文字,所以我把它整理成了这篇博客——内容一一对应,只是从「讲」改成了「写」,顺手补全了几处当时没展开的逻辑。文中引用到的链接,都会在文末一并附上,方便大家查证。
这场分享的起点是一句随口的话:这几年「Agent 开发」这个词一直在变,去刷 Boss 直聘的 JD,更新得飞快。我想聊的是——在这么快的迭代下,无论你在找实习,还是已经在做 Agent 开发,该用什么心态去接住它。
TL;DR
- 名词(Prompt → Context → Harness → Loop)换得比模型还快,但它们做的是同一件事:围着不变的模型核心,一层层往外搭系统。
- 不被新词淹没:别囤着不看,先丢给你的个人 agent 过一遍;学新东西先扒 JD、抓一手资料,别让 AI 从零教你。
- 真正的护城河不是知识(知识是白菜,AI 能批量产),而是你的判断、品味和 context;而 context 来自主动——造东西、公开、被检验。
- 一句话:与其追每个名词,不如建一个能自己跑下去的系统——技术上是你的常驻 agent,成长上是「做 → 踩坑 → 沉淀 → 公开」的闭环。
整篇分四块:名词这一年到底在讲什么、我怎么不被它们淹没、怎么有目的地学、以及真正的护城河是什么。
一、名词这一年:四拨工程接力,一整年的开源浪潮#
新词太多,遇到新词会焦虑,这很正常。所以先同步背景,把这几个词到底在讲什么捋清楚。
把这几年的关键词排成一条线,会看到一条清晰的接力:
- ‘22–‘23 Prompt Engineering —— 把一句话写好。讲究怎么通过提示词,让 LLM 返回更高质量、更稳定的回答。那时候还流行各种 magic words:「回答前先想一步」「回答前再反思一下」之类。(随 GPT-3 / ChatGPT 普及,可参考 Prompt Guide ↗)
- ‘25.6 Context Engineering —— 管好模型「看到的一切」。任务一长,模型的注意力就涣散,于是重点变成:如何让它注意力集中,以及只喂它真正需要的 context。由 Shopify CEO Tobi Lütke 提出,Karpathy ↗ 推火。
- ‘26 初 Harness Engineering(驾驭工程) —— 给模型套上「脚手架」。OpenAI Codex ↗ 和 Anthropic ↗ 那两篇博客有个共同的关键词:long-running。想让 agent 干更长的任务,就得引入 harness。
- ‘26.6 Loop Engineering —— 别再手动 prompt,去设计「循环」。OpenClaw 作者 Steinberger 的一条推 ↗(大意是「你不该再给 coding agent 敲 prompt,而该去设计 prompt 它们的循环」)拿下 1.7M 播放、引爆讨论,Addy Osmani ↗ 随后把它系统化、正式命名。
这四个,是同一条「工程名词」的接力:Prompt → Context → Harness → Loop。而在它们中间,还垫着一整年的行业背景——2025 是公认的「Agent / multi-agent 元年」:开源框架遍地开花(LangChain deepagents ↗、Goose……),大厂和初创都在做 agent、推 multi-agent,直到年底才有人开始反思 multi-agent 是不是伪需求。它本身不是一个新的「工程名词」,而是上面那四拨接力得以发生的土壤。
把时间摊开看更直观:从 Prompt 到 Context,中间隔了三四年;而 Context 之后的 Harness、Loop,连同 2025 那波开源浪潮,几乎全挤在这一年里。火到什么程度——连腾讯两周前那份三万字报告 ↗,都还停在「驾驭工程」,Loop 是这周才冒出来的。我估计再过两周,小红书、Boss 直聘上就会出现「招 Loop Engineering 实习生」,毕竟现在的 JD 还停留在 OpenClaw 和 harness 那个时代。
规律:工程的「对象」一直在向外扩#
把这几拨叠在一起看,会发现一件事——模型基本没变,变的是你下手的「那一圈」:

一句话:词 → 上下文 → 环境 → 机制。 名词在变,但它做的事是同一件——围着那个不变的模型核心,一层层向外搭一个系统。换句话说,这条名词演进史,本身就是一部「系统不断向外扩」的历史。
这不只是炒作:同一个模型,只改外面那圈#
给一组很硬的数据。LangChain 的 coding agent,模型(gpt-5.2-codex)一行没动——这模型还是闭源的——他们只重做了 harness,就在 Terminal-Bench 2.0 ↗ 上从 Top 30 开外(52.8%)冲进了 Top 5(66.5%),整整 +13.7 分,约等于白嫖了一整代模型的进步。那篇博客 ↗的作者 Vivek Trivedy(在 LangChain 带开源 agent 和 harness)有句话很到位:
「Agent = 模型 + Harness。你要么是模型,要么就是 harness——模型之外的一切,都是 harness。」
还有一个更微妙的例子。我之前用 Grok 的 coding 模型,它的工具调用一直有问题——参数对不上,经常调用失败。我印象里有研究做过这样的实验:把参数格式对齐之后,同一个模型的表现直接拔高了近一个量级。所以很多看起来是「模型不行」的问题,本质是 harness 没做好。
小声说一句:上面这个实验,我一时找不回原始出处了,是凭印象写下的,等找到会回来补上链接——也欢迎知道出处的读者帮忙指正。
名词的本质:换的是名字,做的是同一件事#
再往回推:我们更早做的 prompt、context,本质也都是 harness,只是那时候「harness」这个词还没出现而已。
而且上一层从没消失,只是变成了下一层的一个零件。Prompt 没死,它成了 Loop 里的一个组件——原本是人类手动打磨一个更好的 prompt,Loop 则是让 agent 在循环里自己打磨 prompt、自动测试、自动迭代。本质还是一层包一层,而且很多时候前一层早就在做了,只是没被单独命名。
所以名词为什么一直在换?一部分是真有增量(Loop 相对 harness 确实多了东西,得承认),但很大一部分原因是它需要炒作。大可不必一看到新名词就发怵。它们做的始终是同一件事:在不改模型本身的前提下,让一个 agent 更稳、让体验比直接用 ChatGPT / Claude 更好。这件事,我管它叫 Agent Engineering。
二、为什么我不焦虑#
很多人看到一堆新名词,第一反应是「天,我有好多东西要学」。但问题往往不是名词太多,而是你「囤着却不看」。
新名词像 DDL 一样越堆越高,可大多数人只是把它们收藏起来,从不花时间真正搞懂——总以为「收藏 = 看过」。这件事我自己也干过。但如果你真去算成本,会发现读懂一个新概念(比如 Loop Engineering)远没有想象中贵。焦虑的来源从来是「未知」本身:堆起来的不是知识,是未知。这一点想透,就好办了。
做法一:看到新东西,先丢给我的个人 agent#
比如我看到 Loop Engineering,那条原推挺长,我没空细读,就直接丢给我的 agent:「帮我过一遍,讲清楚这是什么,最近很火。」
有了 AI,快速、片面地了解一个新东西,成本极低。光看它的解读,我就大致知道这东西是什么了——这就够。觉得有意思,再去精读;觉得没必要,就跳过。很多新内容根本不需要逐字读,让 AI 先读一遍就好。
而且它常常顺手告诉我:我基于自己设备搭的那些 cron job、skills、workflow,其实很多早就是 Loop Engineering 了。这恰好印证了前面那句——新名词很多时候只是给「大家早就在做的事」起了个新标签。
做法二:别问「它是什么」,问「它跟我做的有什么不同」#
这个问法的前提,是你的 agent 得了解你(有记忆),或者你直接把它放进你的 codebase 里问。
然后你问它:这个新东西,跟我已经在做的差在哪? 这样就能把新名词归到三类里——真东西、值得追;我其实早就在做;纯炒作、跳过。哪怕你完全不懂这个新东西,你也得知道自己跟它的差距是什么、要补什么、做哪些实践才能追上。能分清这三类,你就不会被每个新词牵着走。
三、怎么学 & 上哪找信息#
很多人怕信息差:「我接触不到一手信息」「我是不是比别人慢了一步」。网上还每天有人吓你「不学这个 CC / Codex 技巧你就废了」——这些大多是在制造焦虑。
学新东西,第一步不是学,是扒 JD#
我学东西很功利:奔着就业,也奔着把东西做出来。所以上手一个新方向,我会先扒一堆 JD,看这行在用哪些术语。比如最近想学 agentic RL,我直接去搜有点名气的大厂、和顶级初创的岗位。
为什么先看 JD?因为知道了术语,你搜资料、跟 AI 聊,才问得准,才会建立起对这个行业的基本认知。前提是你要学的方向市面上已经有岗位(像 agent 这种相对成熟、又在快速发展的方向就很合适);如果还没有岗位,那只能退而求其次靠搜索和博客了。
有个坑要避开:别去看那种很初创、很小厂的 JD,他们的 JD 多半是 vibe 出来的,没有参考价值。
信息源上,我的建议是优先看 X(推特)和官方博客(OpenAI / Anthropic)。国内公众号里当然有好的,但我接触到的那批,普遍标题党、信息密度低——一手信号在 X 和官博,公众号大多是二手转述。
别让 AI 从零教你一个新领域#
这是个值得说清楚的坑。大模型有两个当前普遍的局限:一是会顺着你——你怎么问,它就顺着你的预设往下接;二是在你完全没有基础时,它产生的幻觉你根本无从分辨(这是现阶段所有大模型的通病,不是某一个模型的问题)。
两者叠加,如果你零基础、又把「教学」整个甩给 AI,很容易越学越偏:它给你一份看似体面的「学习路线」,你判断不了对错,它再顺着你强化,最后学到的是一套自洽但失真的东西。
正确的顺序是反过来的:
- ❌ 从零让 AI 教 —— 让它直接给一份「学习路线」→ 你没基础、判断不了对错 → 它还顺着你 → 越学越歪。
- ✅ 先抓一手 —— 扒 JD、或让它推荐几篇好博客 → 自己读原文,建立属于你的「唯一真相」→ 卡住了,再带着具体问题去问它。
我学一个新领域时,会先让 AI 推荐几篇好博客,而不是让它从零开讲。博客里一定有我看不懂的,我再把那部分丢回去让它解答——这样它也能基于我的学习路线,建立起对我当前阶段的认知。
体力活,交给 agent#
与其每天刷信息,不如让自己的 agent 当过滤器,你只接收筛过的那一小撮:

这里有个容易踩的坑:直接让 LLM「推荐几篇论文」,它很可能编出根本不存在的标题和链接。更稳的做法,是给它接上真实可信的工具——比如调用 arXiv 的 skill(本质是 web extract,直接从源站抓取),拿回来的就是真链接、真元数据,而不是模型脑补的。拿到候选之后,再加一步核实校验:让 agent 逐条确认链接可达、标题和摘要对得上,再进入筛选和摘要。
另一个简单好用的启发式:判断一篇论文值不值得追,先看它有没有开源代码库——粗暴,但有效。
要强调一点:不是什么都该甩给 AI。恰恰因为有了 AI,你更需要独立的学习能力和深度思考——哪些博客、论文要自己一行行精读,哪些可以交给 agent 直接做完,这个判断只能由你来下。
每个人都该有一个带长期记忆的个人 agent#
如果你用过 OpenClaw 或 Hermes Agent,会知道它本质就是一个常驻 agent——你通过 WhatsApp / Telegram 跟它对话。它的架构大致是这样:
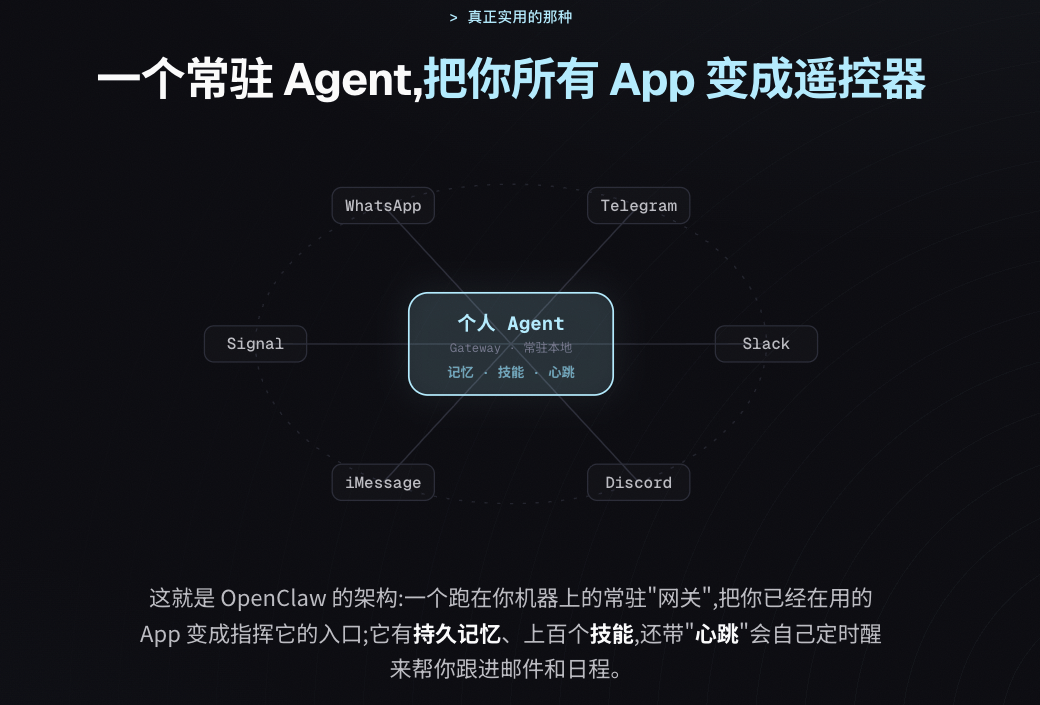
一个跑在你机器上的常驻「网关」,把你已经在用的 App 变成指挥它的入口;它有持久记忆、上百个技能,还带「心跳」——会自己定时醒来,帮你跟进邮件和日程。
我认为现在每个人都该有这样一个带长期记忆的个人 agent——哪怕它的长期记忆现在还很粗糙。因为你自己写 skills、自己长期深度地用,会撞上一堆真实的坑,而这些经验,正是你在面试里、在与人交流时最有分量的东西。说到底,这就是前面那条主线里「技术那一层的系统」:一个能自己跑起来、替你处理信息洪流的东西。
四、真正的护城河:主动性#
这一部分的起点,是我 mentor 的一句话:「面试,是我们这一行唯一的护城河。」
这句话我到现在依然认同,但理解变了。我曾经把它当字面意思,拼命去刷面试;后来我更愿意把「面试」读成一种学习方式——它真正的内核,是逼你不断把自己暴露在外部检验之下、不闭门造车。顺着这个内核往下,路径其实不止面试:进交流群、打黑客松、参加 workshop,本质都是同一件事。(当然我也得承认:有些面试、尤其是小公司的,确实既费时又费心情,不必为了刷而刷。)
而所有这些「把自己推出去被检验」的动作,背后是同一种东西——主动性。这才是那条真正的护城河。
知识是地基,Context 才是护城河#
这里引用 Dan Koe ↗ 的一个区分(你可以当它是鸡汤,我也觉得他不少文章偏鸡汤,但这点很对):我们要做的是 context creator,不是 content creator。
- 知识(content) —— fact-based、可被批量生产。AI 几乎是无限供给,它越来越像白菜:谁都拿得到,所以谁也不靠它取胜。
- Context —— 你的判断、你的品味、你走过的路、你踩过的坑。这是 AI 替不掉、也无法批量生产的部分。
但有件容易被误读的事要讲清楚:说知识「是白菜」,不是说它不重要,而是说它易得、不构成差异。 学一个新领域,你依然必须先有扎实的基础认知打底——没有地基,你既读不懂一手资料,也判断不了 AI 有没有在胡说。基础认知是门票,真正的护城河,是你在这块地基之上、围绕你这条赛道长出来的 Context。知识易得,Context 难求,顺序不能反。
放到面试里就很具体:「skills 是什么」——AI 能答,甚至一字不差、百分百正确。但你能讲的是:你用过哪些 skills、它们各自的好与坏、你踩过什么坑、你怎么取舍。这些 AI 替不了。腾讯报告把它说得更狠:AI 替代的,是「你被雇佣的理由」。
这也是为什么我对培训班项目、以及没有二次开发的开源项目都比较抵触——这类东西 AI 自己就能做出来,那我为什么要招一个「AI 能做出来的人」?我想看到的,是你身上 AI 替代不掉的那部分,包括品味。一个很现实的例子:有审美的人做出来的前端,就是比你好看,哪怕他们用的是 Google AI Studio 这种「没那么高级」的工具。很多 PM、设计师做出来的东西,就是比纯开发群体好看不少——所以纯开发的我们,也得补一补审美这一课。
赢的人,不一定最懂技术,但一定最主动#
腾讯那份《超级个体时代》报告 ↗把「超级个体」拆成四种能力,我觉得很到位:
- AI First —— AI 是工作的默认起点。前几天面试,面试官问我「你还手写代码吗」,我说确实没有了。我上大学的时间,恰好和 AI 变得很强重叠,所以天然就 AI First;而经历过「传统古法编程」时代的人,要转这个思维反而更难。
- 能力跃迁 —— 量级提升 + 跨域闭环。类似现在大家为什么都招全栈、而不再分前端后端——AI 把单人能覆盖的范围抬高了不止一个维度。再往后,可能还会出现「产品开发工程师」,开发的同时还得兼顾一点增长。
- 主动探索 ← 这条最关键:主动去逼近 AI 能力的边界。
- 影响力溢出 —— 让团队一起变快。
报告里还有句话我特别认同(也是我实习公司特赞创始人范凌的观察):用 AI 用得最好的,往往不是研发,而是产品经理和设计师。 在这家公司实习,我深有体会——第一个想到用 AI 做视频的,是剪辑师。很多时候,思维真得跳出去一步。
AI 几乎把所有人的能力拉回了同一条起跑线,这时候「主动性」就成了最稀缺的东西。
把学习痕迹公开,让它变成一个循环#
具体怎么主动?把你学习的路径、痕迹公开出来,让它转成一个循环:
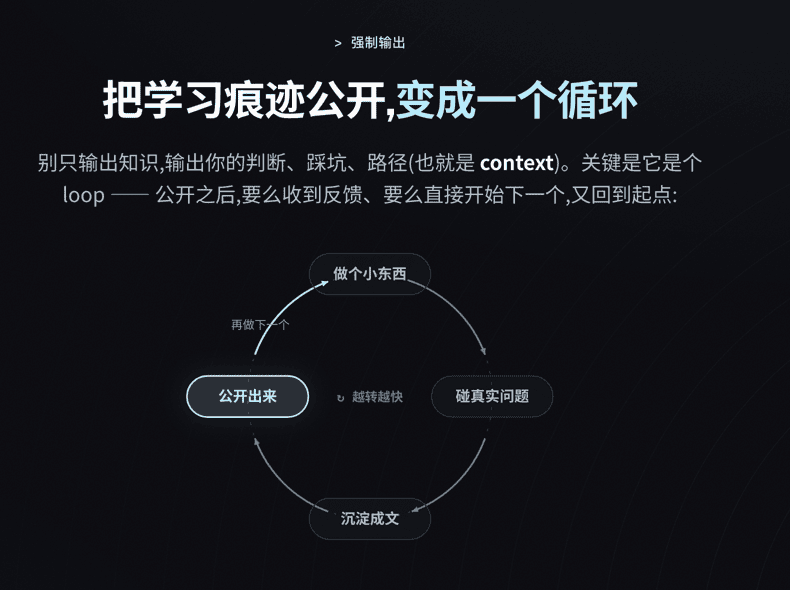
先做个小东西,你一定会撞上真实问题,把它沉淀成文章 / skills / 笔记,然后公开——博客、视频、自媒体都行,再简单点,发到社群里也算。公开之后,要么收到反馈、要么直接开始下一个,又回到起点。
这就是那条主线里「成长那一层的系统」——和你的个人 agent 形状一模一样,只不过跑的是你自己。关键是:别只输出 content(知识),要输出你的判断、踩坑、路径(也就是 context)。 而且「公开」这件事本身会倒逼你输出——有点像做理科题,你要真会一道题,得能讲清楚给别人听。这篇分享,就是我把过去不到一年的心得逼自己沉淀出来的产物。
为什么这对年轻人是好事:迭代越快,起跑线越平#
现在很多公司不只卡学历,还卡年龄——「我们只要 00 后」「只要 90 后」。学历你还能靠外面够硬的项目补回来,年龄是真补不回来的。
但反过来想:没有人有「十年 Loop Engineering 经验」。 最资深的工程师和你,这周读的是同一条推。
资历会过期,好奇会复利——弯道超车,就是这么来的。
弯道超车具体怎么切:去做测评#
讲个很新的。Vercel 这周(6/12)的 AI SDK 更新 ↗,让你能像换模型一样换 harness——Claude Code / Codex / Pi,同一套 API,各自跑在自己的沙箱里:
const agent = new HarnessAgent({
harness: claudeCode, // 也可换 codex / pi
sandbox: createVercelSandbox()
})harness 第一次被官方做成了标准化的工程层。而它真正的连锁反应在这儿:当 harness 能像换模型一样随便换,「横向比较哪个 harness 更好」——也就是测评——才第一次变得既容易、又值钱。 可偏偏,Agent 的测评本来就少之又少,这个刚被撬开的口子,几乎没人系统地做过。
所以「做测评」就是最实在的切入点。我在博客里反复提过:你实习的项目、你自己的项目,只要有时间有能力就去做测评。 做测评你会撞上一大堆真实问题;不做测评,你的 agent 就是个黑盒,根本没法用。而且测评这套很吃香——上周那位做车载(很垂类)的同学,就因为做了测评,攒了一堆很真实的案例和经验,能直接喂进他接下来的工作。
最后:把焦虑,换成两个动作#
- 造一个真东西 —— 哪怕只是个很小的 agent,先让它碰到真实问题。
- 公开你的学习痕迹 —— blog、小红书、GitHub 都行,输出 context,不只是 content。
名词会一直变。但无论在技术上、还是在成长上,你真正需要的是同一样东西——一个能自己跑下去的系统。 技术上,它是一个有记忆、有技能、会自己醒来的常驻 agent;成长上,它是一个「做点东西 → 碰到真问题 → 沉淀 → 公开 → 再做下一个」的闭环。两个系统,同一个形状:你把它搭好,它就替你对抗这片永远在变的噪音。
名词只是噪音,系统才是信号。讲完了——有问题欢迎来群里 / 评论区聊。
— Joye · joyehuang.me ↗
参考链接#
- Prompt Engineering:promptingguide.ai ↗
- Context Engineering(Karpathy):x.com/karpathy ↗
- 开源 Agent / deepagents:github.com/langchain-ai/deepagents ↗
- Harness Engineering — OpenAI Codex:openai.com ↗
- Harness Engineering — Anthropic:anthropic.com ↗
- Loop Engineering — Steinberger 原推:x.com/steipete ↗
- Loop Engineering — Osmani 命名博客:addyosmani.com ↗
- LangChain · Harness 实测博客:langchain.com ↗
- Terminal-Bench 2.0 榜单:tbench.ai ↗
- Dan Koe · context vs content:letters.thedankoe.com ↗
- 腾讯研究院《超级个体时代》:news.qq.com ↗
- Vercel AI SDK · Harness:vercel.com ↗