From Interviews to Agent Engineering: Why I Stay Calm
Prompt -> Context -> Harness -> Loop: terms change faster than models, but the work is the same-build systems that keep running.
Last week I gave a technical sharing session in my follower group. The video is already out, but some people prefer reading, so I turned it into this post. The structure maps one-to-one to the talk, just rewritten from spoken notes into an article, with a few arguments filled in more fully. All links referenced in the post are collected at the end.
The talk started from an offhand observation: the words around “Agent development” keep changing, and job descriptions on Boss Zhipin update painfully fast. What I wanted to discuss was this: when the field iterates this quickly, whether you are looking for an internship or already building agents, what mindset should you use to keep up with it?
TL;DR
- Terms change faster than models - Prompt -> Context -> Harness -> Loop - but they are all doing the same thing: building more system around the stable model core.
- Do not drown in new terms. Do not hoard links and never read them. Send them through your personal agent first; when learning a new area, scrape job descriptions and primary sources instead of letting AI teach you from zero.
- The real moat is not knowledge. Knowledge is abundant and AI can mass-produce it. The moat is your judgment, taste, and context; context comes from initiative - building, publishing, getting tested.
- In one sentence: do not chase every term; build a system that keeps running. Technically, that is a persistent personal agent. For your growth, it is a loop of build -> hit real problems -> distill -> publish.
This post has four parts: what these terms are really about, how I avoid getting overwhelmed, how I learn deliberately, and what the real moat is.
1. A year of terms: four engineering waves and a year of open-source agents#
There are too many new words. Feeling anxious when you see them is normal. So let us first align on what these words actually mean.
If you put the keywords from the past few years on one line, you get a clear relay:
- ‘22-‘23 Prompt Engineering - write the instruction well. The focus was on prompting an LLM to return better and more stable answers. Back then, people were still obsessed with magic words like “think step by step” and “reflect before answering.” See Prompt Guide ↗.
- ‘25.6 Context Engineering - manage everything the model sees. As tasks get longer, model attention drifts, so the problem becomes: how do we keep attention focused and feed only the context that matters? Shopify CEO Tobi Lutke proposed it, and Karpathy ↗ made it catch fire.
- Early ‘26 Harness Engineering - wrap the model in scaffolding. The OpenAI Codex ↗ and Anthropic ↗ posts share one important word: long-running. If you want an agent to work on longer tasks, you need a harness.
- ‘26.6 Loop Engineering - stop manually prompting and design the loop instead. A tweet by Steinberger ↗, the creator of OpenClaw, roughly argued that you should not be typing prompts for coding agents anymore; you should design the loops that prompt them. It hit 1.7M views and started a broader discussion. Addy Osmani ↗ then systematized and named it.
These four terms are one relay of engineering vocabulary: Prompt -> Context -> Harness -> Loop. In between sits the broader industry backdrop: 2025 was widely treated as year one for Agent / multi-agent systems. Open-source frameworks bloomed everywhere - LangChain deepagents ↗, Goose, and many more. Big companies and startups all built agents and pushed multi-agent architectures, until by the end of the year people started questioning whether multi-agent was sometimes fake complexity. Multi-agent itself is not a new “engineering term” in this chain; it is the soil that made the four waves happen.
The timeline makes the compression obvious: Prompt to Context took three or four years. After Context, Harness and Loop, plus the 2025 open-source agent wave, almost all arrived in one dense year. It moved so fast that Tencent’s 30,000-word report ↗ from two weeks ago was still centered on Harness Engineering; Loop only appeared this week. I would not be surprised if Xiaohongshu and Boss Zhipin start showing “Loop Engineering Intern” roles in two weeks. Right now the job descriptions are still stuck in the OpenClaw and harness era.
The pattern: the engineering target keeps expanding outward#
Put these waves together and one thing becomes clear: the model basically stays the same; what changes is the layer you operate on.

In one line: words -> context -> environment -> mechanism. The names change, but the work is the same: build a system outward around the model core. In other words, the history of these terms is a history of the system boundary expanding.
This is not just hype: same model, better outer layer#
Here is a hard number. LangChain’s coding agent did not change the model at all (gpt-5.2-codex, still a closed model). They only rebuilt the harness, and on Terminal-Bench 2.0 ↗ they jumped from outside the top 30 (52.8%) into the top 5 (66.5%), a gain of 13.7 points - almost the kind of lift you would expect from a new model generation. Vivek Trivedy, who leads open-source agents and harness work at LangChain, put it well in that post ↗:
“Agent = model + harness. You are either the model, or you are the harness - everything outside the model is harness.”
There is a subtler example too. When I used Grok’s coding model before, its tool calling kept failing because arguments did not match the expected schema. I remember seeing research where simply aligning parameter formats made the same model perform nearly an order of magnitude better. So many problems that look like “the model is bad” are really harness problems.
Small caveat: I cannot find the original source for that experiment right now, so I am writing from memory. I will add the link if I find it, and if you know the source, please point me to it.
The essence: the name changes, the work does not#
Go backward and you will see that earlier prompt and context work were also harness work; the word “harness” just did not exist yet.
And the previous layer never disappears. It becomes a component of the next layer. Prompting did not die; it became one component inside a loop. Before, humans manually refined a better prompt. With Loop Engineering, agents refine prompts, run tests, and iterate inside the loop. It is layers wrapping layers. Often the old layer was already being used; it just had not been named separately.
So why do the terms keep changing? Partly because there are real increments - Loop does add something beyond harness, and we should admit that. But a large part is also marketing. There is no need to panic every time a new term appears. They are doing the same underlying job: without changing the model itself, make an agent steadier and make the experience better than directly using ChatGPT or Claude. I call that Agent Engineering.
2. Why I am not anxious#
When people see a pile of new terms, their first reaction is often: “I have so much to learn.” But the problem is usually not that there are too many terms. The problem is that you save them and never read them.
New terms pile up like deadlines. Most people only bookmark them and never spend the time to understand them. They quietly pretend that “saved” means “read.” I have done this too. But if you calculate the actual cost, understanding a new concept like Loop Engineering is much cheaper than it feels. Anxiety comes from the unknown itself. What piles up is not knowledge; it is unknowns. Once you see that, the solution is straightforward.
Practice 1: send new things to my personal agent first#
For example, when I saw Loop Engineering, the original tweet was long and I did not have time to read it closely. I sent it straight to my agent: “Read this and explain what it is. It seems to be getting popular.”
With AI, the cost of quickly and partially understanding something new is extremely low. From its explanation alone, I roughly understood what the thing was. That was enough. If it looked important, I could read the original carefully; if not, I could skip it. Most new material does not deserve a line-by-line read. Let AI do the first pass.
It often tells me something useful along the way: many cron jobs, skills, and workflows I built on my own devices were already basically Loop Engineering. That validates the earlier point: new terms often just label things many people were already doing.
Practice 2: do not ask “what is it”; ask “how is it different from what I already do?”#
This requires your agent to know you, either through memory or by being placed inside your codebase.
Then ask it: how is this new thing different from what I am already doing? That lets you sort new terms into three buckets: a real thing worth chasing; something I am already doing; or pure hype I can skip. Even if you do not fully understand the new thing yet, you need to know the gap between it and your own work, what you would need to learn, and what practice would close that gap. If you can sort terms this way, they stop dragging you around.
3. How to learn and where to find information#
People are afraid of information gaps: “I cannot reach primary sources” or “am I already behind?” Meanwhile, the internet keeps telling you that you are doomed if you do not learn some new Claude Code / Codex trick. Most of that is anxiety manufacturing.
The first step in learning is not studying. It is scraping job descriptions.#
I learn very pragmatically: for employability and for building real things. So when I enter a new direction, I first scrape a pile of job descriptions and look at the terms the market is using. Recently, when I wanted to learn agentic RL, I searched for roles from recognizable large companies and top startups.
Why start from job descriptions? Because once you know the vocabulary, you can search and talk to AI precisely, and you can start building a basic map of the field. This works when the direction already has real jobs, which is true for a relatively mature and fast-moving area like agents. If there are no jobs yet, you have to fall back to search and blogs.
One trap: do not take very early-stage tiny-company job descriptions too seriously. Their JDs are often vibe-generated and not very useful.
For information sources, I recommend X/Twitter and official blogs first - OpenAI, Anthropic, and so on. There are good Chinese newsletters too, but many of the ones I see have clickbait titles and low information density. Primary signals are on X and official blogs; WeChat articles are often second-hand retellings.
Do not let AI teach you a new field from zero#
This is a trap worth spelling out. Current large models have two common limitations. First, they tend to follow your framing. However you ask, they continue along your assumptions. Second, when you have no foundation at all, you cannot detect hallucinations. This is a general limitation of current models, not one model’s fault.
Combined, these two problems are dangerous. If you are starting from zero and hand the entire “teaching” job to AI, it is easy to drift. It gives you a polished-looking learning path, you cannot judge whether it is right, and then it reinforces the direction you asked for. You end up with a self-consistent but distorted map.
The correct order is the reverse:
- Wrong: let AI teach from zero - ask it for a learning path -> you lack the foundation to judge it -> it follows your framing -> you drift.
- Right: capture primary sources first - scrape job descriptions or ask for a few good blogs -> read the originals and build your own source of truth -> when stuck, ask AI specific questions.
When I learn a new field, I ask AI to recommend a few good blogs, not to lecture from scratch. There will definitely be parts I do not understand. I then send those parts back and ask for help. That way, the model is anchored to my learning path and can understand my current stage.
Give the manual labor to agents#
Instead of reading the information stream all day, let your agent act as a filter. You only receive the small set worth reading:

One common pitfall: if you ask an LLM to “recommend a few papers,” it may invent titles and links. The safer approach is to connect it to real, trusted tools - for example, an arXiv skill that extracts data from the source site. Then the results are real links and real metadata, not model imagination. After collecting candidates, add a verification step: have the agent confirm that each link is reachable and that the title and abstract match before summarizing and filtering.
Another simple heuristic: to decide whether a paper is worth tracking, first check whether it has an open-source repo. Crude, but useful.
To be clear, not everything should be handed to AI. Precisely because AI exists, independent learning and deep thinking matter more. You still have to decide which blogs and papers deserve careful reading, and which tasks can be fully delegated to an agent.
Everyone should have a personal agent with long-term memory#
If you have used OpenClaw or Hermes Agent, you know the shape: a persistent agent that you talk to through WhatsApp or Telegram. The architecture roughly looks like this:
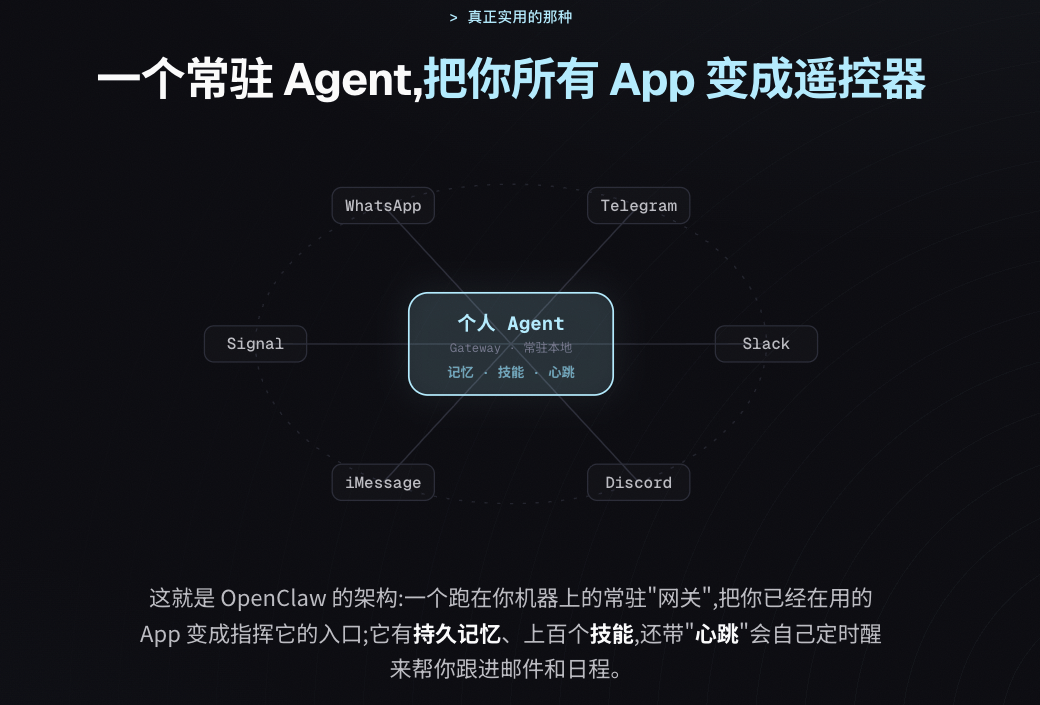
It is a persistent gateway running on your machine, turning the apps you already use into command surfaces. It has persistent memory, hundreds of skills, and a heartbeat that wakes itself up on a schedule to help you follow up on email and calendar items.
I think everyone should have this kind of long-memory personal agent now, even if long-term memory is still rough today. When you write your own skills and use it deeply over time, you hit real problems. Those experiences are exactly what carry weight in interviews and technical conversations. This is the technical-system version of the main theme: something that runs on its own and helps you process the information flood.
4. The real moat: initiative#
This part starts from something my mentor once said: “Interviewing is the only moat in our field.”
I still agree, but I now understand it differently. I used to take it literally and grind interviews. Now I read “interviewing” more as a learning method. Its real core is forcing yourself into external evaluation instead of building behind closed doors. If that is the core, interviews are not the only path: group discussions, hackathons, and workshops are all versions of the same thing. Of course, I also admit that some interviews, especially at small companies, are tiring and not worth doing just for practice.
Behind all these actions - pushing yourself out to be tested - is one thing: initiative. That is the real moat.
Knowledge is the foundation. Context is the moat.#
Here I want to borrow a distinction from Dan Koe ↗. You can treat some of his writing as motivational fluff, and I often do, but this point is right: we should become context creators, not just content creators.
- Knowledge / content - fact-based and mass-producible. AI supplies it almost infinitely. It is increasingly like cabbage: everyone can get it, so it does not differentiate you.
- Context - your judgment, taste, path, and scars. This is the part AI cannot replace or mass-produce.
One misunderstanding needs to be cleared up: saying knowledge is “cabbage” does not mean knowledge is unimportant. It means knowledge is easy to obtain and therefore not the differentiator. When learning a new area, you still need a solid foundation. Without it, you cannot read primary sources and cannot tell whether AI is hallucinating. Foundational knowledge is the ticket. The real moat is the context you grow on top of it around your own path. Knowledge is easy to get; context is hard. Do not reverse the order.
In interviews, this becomes concrete. “What are skills?” AI can answer that perfectly. What you can answer is: which skills you have actually used, what was good and bad about them, what pitfalls you hit, and how you made tradeoffs. AI cannot replace that. Tencent’s report puts it more brutally: AI replaces “the reason you were hired.”
That is why I am skeptical of bootcamp projects and open-source projects with no substantial second-pass development. AI can produce those. Why would I hire someone who only proves they can build what AI can already build? I want to see the parts AI cannot replace, including taste. A very practical example: people with stronger visual taste often build better frontends, even if they use tools like Google AI Studio that developers may consider “less advanced.” Many PMs and designers produce better-looking interfaces than pure developers. So we developers need to train taste too.
The winner is not always the most technical. It is the most proactive.#
Tencent’s Super Individual Era report ↗ breaks “super individuals” into four capabilities. I think the framing is useful:
- AI First - AI is the default starting point for work. In an interview a few days ago, the interviewer asked me whether I still hand-write code. I said: honestly, not much. My university years overlapped with AI becoming extremely capable, so AI First feels natural to me. People who lived through the older era of traditional programming often find this mindset shift harder.
- Capability leap - order-of-magnitude improvement plus cross-domain loops. This is similar to why teams now hire full-stack engineers instead of neatly separating frontend and backend. AI has lifted the scope one person can cover. Later, we may see more “product development engineers” who build and also understand growth.
- Active exploration - this is the most important one: proactively pushing toward the boundary of AI capability.
- Influence spillover - making the whole team faster.
The report also says something I strongly agree with, and it matches what Fan Ling, the founder of Tezign where I interned, has observed: the people who use AI best are often not engineers, but product managers and designers. I felt this directly during my internship. The first person to think of using AI for video was an editor. Often you really do need to jump outside the engineering frame.
AI has pulled almost everyone back toward the same starting line. In that world, initiative becomes the scarce thing.
Make your learning trail public and turn it into a loop#
So how do you become proactive? Make your learning path and traces public, and turn them into a loop:
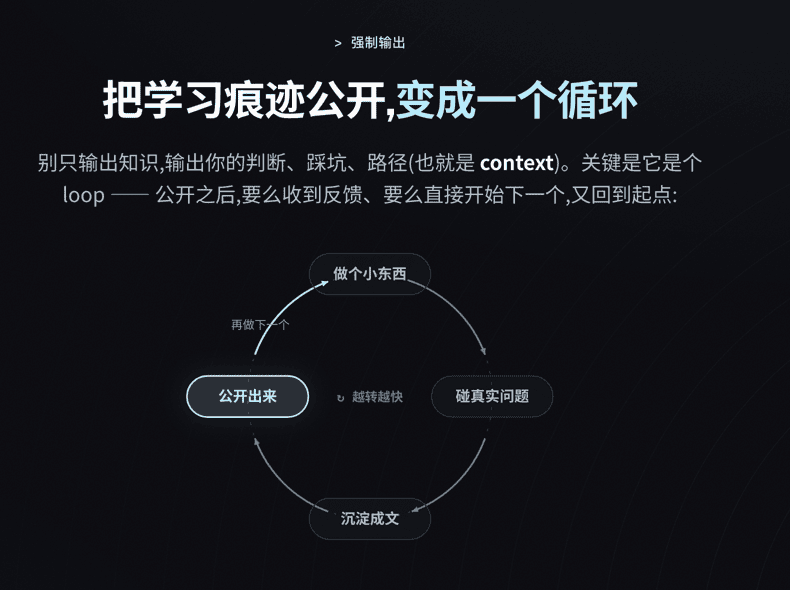
Build a small thing first. You will hit real problems. Distill those problems into articles, skills, or notes, then publish them - on a blog, in videos, on social media, or simply in a community group. After publishing, you either receive feedback or start the next thing, and you return to the beginning.
This is the growth-system version of the main theme. It has the same shape as your personal agent, except it runs on you. The key is: do not only output content; output your judgment, pitfalls, and path - your context. Publishing also forces clarity. It is like solving a science problem: if you really understand it, you should be able to explain it to someone else. This talk itself is me forcing myself to distill less than a year of experience into something public.
Why this is good news for young people: faster iteration flattens the starting line#
Many companies do not only filter by school; they also filter by age - “we only want people born after 2000,” or “only post-90s.” A weaker school background can sometimes be compensated for with strong external projects. Age cannot be compensated for.
But the reverse is also true: no one has ten years of Loop Engineering experience. The most senior engineer and you are reading the same tweet this week.
Credentials expire. Curiosity compounds. That is what overtaking on a curve looks like.
A concrete way to overtake: do evaluation#
Here is a very recent example. Vercel’s AI SDK update ↗ this week (6/12) lets you swap harnesses the way you swap models - Claude Code, Codex, Pi, all behind the same API, each running in its own sandbox:
const agent = new HarnessAgent({
harness: claudeCode, // can also be codex / pi
sandbox: createVercelSandbox()
})For the first time, harness is being standardized as an official engineering layer. The real chain reaction is this: once harnesses can be swapped as easily as models, comparing which harness is better becomes both easy and valuable. In other words: evaluation. And agent evaluation is still scarce. This opening has barely been explored systematically.
So “do evaluation” is a very practical entry point. I have said this repeatedly on my blog: for your internship project or personal project, if you have the time and ability, do evaluation. Evaluation forces you into real problems. Without evaluation, your agent is a black box and you do not know whether it works. Evaluation is also valuable in the job market. Last week, a student working in automotive, a very vertical domain, had done evaluation and accumulated many real cases and lessons. Those could directly feed into his next job.
Finally: turn anxiety into two actions#
- Build a real thing - even a tiny agent is enough. Let it touch real problems first.
- Publish your learning trail - blog, Xiaohongshu, GitHub, anything. Output context, not just content.
Terms will keep changing. But technically and personally, what you need is the same thing: a system that keeps running. Technically, it is a persistent agent with memory, skills, and a heartbeat. Personally, it is a loop of “build something -> hit a real problem -> distill -> publish -> build the next thing.” Same shape, two systems. Once you build it, it helps you fight the noise that never stops changing.
Terms are noise. Systems are signal. That is the talk. If you have questions, come chat in the group or comments.
- Joye · joyehuang.me ↗
References#
- Prompt Engineering: promptingguide.ai ↗
- Context Engineering (Karpathy): x.com/karpathy ↗
- Open-source Agent / deepagents: github.com/langchain-ai/deepagents ↗
- Harness Engineering - OpenAI Codex: openai.com ↗
- Harness Engineering - Anthropic: anthropic.com ↗
- Loop Engineering - Steinberger original tweet: x.com/steipete ↗
- Loop Engineering - Osmani’s naming post: addyosmani.com ↗
- LangChain harness benchmark post: langchain.com ↗
- Terminal-Bench 2.0 leaderboard: tbench.ai ↗
- Dan Koe on context vs content: letters.thedankoe.com ↗
- Tencent Research Institute, Super Individual Era: news.qq.com ↗
- Vercel AI SDK Harness: vercel.com ↗